Last update 1999/08/07
Scheme処理系の制作 第3回
(C)平山直之
無断転載は禁止、リンクはフリー
誤字脱字の指摘は歓迎
継続とは
今回は、前回「めんどくせえ」と放棄した継続の概念の説明および実装レポートについて書きたいと思います。
あれからまたインターネット漁ってみたのですが、やっぱりどうも日本語リソースはないらしいので、自力で書いてみることにします(schemeの研究してる学者・学生なんて掃いて捨てるほどいるだろうに……)
さて、こんなC言語のコードがあるとします。
void foo(void){
bar(baz( ));
bar(0);
}
C言語を学んだ皆さんなら、このコードがどういう順番に実行されるのかわかりますよね。説明されるまでもなく、
- baz( )を呼び出す
- その戻り値を引数としてbarを呼び出す
- 0を引数として呼び出す
- fooの呼び出しもとに帰る
という順序で実行されるわけです。
このコードに相当するschemeのコードは、こんな感じになります。
(define (foo)
(bar (baz))
(bar 0))
「相当するコード」なので実行順は当然同じです。
C言語などの構造化言語になれきってしまっていると忘れてしまいがちなことですが、実はこれは当たり前のことではありません。C言語でこのような関数呼び出しができるのは、C言語がわざわざそのような処理を舞台裏でしてくれているからに他なりません。「そのような処理」とはすなわち、「スタック(かなにか)を利用して呼び出しもとのコンテキスト(文脈)を覚えていてくれることです。
昔のBASICで、
10 print "foo"
20 goto 50
30 print "baz"
40 end
50 print "bar"
と書いたらどうなるかを考えてみましょう。この場合、goto 50で行番号50に飛んだときに、BASICインタプリタはそれまで自分がどこにいたかを忘れてしまいます。そのため、このプログラムを先頭から実行した場合、行番号30および行番号40は実行されることがありません。そのため、実行結果は
foo
bar
で終わりになり、bazは表示されないのです。
BASICでジャンプ後に戻ってくるようにするには、プログラムを
10 print "foo"
20 gosub 50
30 print "baz"
40 end
50 print "bar"
60 return
と書き換えなければなりません。こうすることによって、gosub命令の実行時にBASICインタプリタが舞台裏で呼び出し時の状況を記憶しておいてくれるため、サブルーチン(gosubの飛び先の行番号50から「return」のある行番号60まで)の実行後に元の場所に戻ってくることができるのです。
アセンブラでも大体同じことが言えます。CやPascalでは、関数(手続き)レベルでは「サブルーチン」が当たり前(というかそれしかできない)ので、気にしなくてもよいようになっているだけなのです。
誤解を恐れずに簡潔に言ってしまえば、コンピュータが何かを実行するときに参考にするこの「状況」こそが継続です。
- すぐ上のBASICのプログラムで言えば、「次に実行する部分を知るために“保持している継続”を使う」と仮定すると、
- 行番号10の実行中は「次に行番号20を実行する」という継続を保持している
- 行番号20の実行中は「次に行番号30を実行する」という継続を保持している。
- 行番号30の実行でサブルーチン呼び出しがあったので、現在保持している「次に行番号30を実行するという継続を待避して「次に行番号50を実行する」と言う継続を保持する。
- 行番号50の実行中は「次に行番号60を実行する」という継続を保持している。
- 行番号60の実行で、復帰のために待避しておいた「行番号30を実行する」という継続を保持する。
- 行番号30の実行中は「次に行番号40を実行する」という継続を保持している。
- 行番号40の実行中は「次に行番号50を実行する」という継続を保持しているが、命令の実行でプログラムを終了する
という一連の動作を行っていることになります。
継続をオブジェクト化せよ!
というわけで、このように言語の舞台裏の装置としては欠かすことのできない「継続」ですが、構造化言語や、学問的にはもっとカッコイイ言語であるところの関数型言語では普通これは表舞台にはでてきません。言うまでもなく、構造化言語には普通大域gotoなんかないし、いちいちgotoなんて考えなきゃいけなかったら構造化の邪魔だからです。構造化言語と関数型言語の中間くらいに位置するとされがちなschemeとてそれは基本的には例外ではありません。
しかしあくまで基本的にはです。call-with-current-continuationという組み込み手続きがこれを覆します。
call-with-current-continuation、長いのでしばしばcall/ccと略されますが、これは1引数をとるschemeの組み込み関数です。
call/ccの引数は関数です。C言語にすら慣れていない人にはちょっとわかりにくいかも知れませんが、schemeでは関数も組み込みデータ型の一つですので、関数の引数として関数を渡すこともできるのです。C言語に慣れている人には、関数ポインタを渡すようなものだと思ってもらえば問題ありません。
scheme(lisp)では「無名関数」というものを作ってそのまま渡すことができる(ここがCの関数ポインタより優れたところの一つです)ので、これを使ってcall/ccを呼び出してみましょう。
(call/cc (lambda (x) x))
lambdaはschemeの構文キーワードで、(lambda (引数リスト)
ボディ)
という式で無名関数を作ることができます(ホントはちょっと違うのだけど、この場合はまあそう思ってよいです)。この式の値が関数ですから、上の式ではlambdaで作った関数をcall/ccに渡すことになるのです。
ここで、(lambda (x) x)を評価すると引数として受け取った値をそのまま返す関数になりますから(分かりますよね?)、ここでこれを
((lambda (x) x) 7)
と単独で呼び出すと、この式全体の値は
7
となると考えて下さい。
さてcall/ccの呼び出し
(call/cc (lambda (x) x))
に戻って考えましょう。call/ccは引数として与えられた関数を、現在の継続を引数として呼び出す関数ですから、この式は結局
((lambda (x) x) 現在の継続)
という関数呼び出しを行ったのと同じことになります。ヤヤコシイですから落ち着いてよく考えてください。
でもって、call/ccを呼び出した場合、基本的には内部で呼び出した関数の戻り値がそのままcall/ccの戻り値になりますので、
(call/cc (lambda (x) x))
の値は
((lambda (x) x) 現在の継続)
と同じ、すなわち
現在の継続
となります。試しにvscheme(私の作った処理系)で試してみましょうか。
(call/cc (lambda (x) x))
#<continuation>
継続は一律#<continuation>と表示する決まりにしてありますので、狙いどおりです。
つまり、こうやって、継続というオブジェクトを取得することができるのです。なんなら変数に束縛することもできます。
(define x ( ))
(call/cc (lambda (cont) (set! x cont)))
これで、xを評価する(vschemeでは入力行にxとだけ入力して改行すればよい)と
#<continuation>
と返されます。ここで、現在の継続とは、call/ccを実行した後に評価すべき式の情報のことです。
オブジェクト化された継続を使う
さて、この継続を実際に使ってみましょう。
schemeでは、継続はそれ自体が1引数を取る関数であると定められています。先ほどのように継続が変数xに束縛されていれば、
(x #t)
のような形で呼び出すことができるということです。
繰り返しますが、むちゃくちゃヤヤコシイので一発で分からないのは当然ですから、落ち着いてゆっくり考えてください。
で、継続を関数として呼び出すと、現在の継続をうっちゃって(東京方言で「どっかにやる≒捨てる)」)その継続を再開します。具体的に言うと、call/cc呼び出しの次に行った(行うべきであった)式の評価を行うということです。で、継続を呼び出すときに与えた引数を、call/ccが返したことになります。
たとえば、
(call/cc (lambda (x) (x #t))
という風にcall/cc呼び出しの内部で引数として与えられた継続を呼び出すと、この式の値は
#t
となります。
継続を大域変数に束縛する
さて、「継続」はschemeのファーストクラスオブジェクトですから、先ほど書いたようにこれを大域変数に束縛することもできます。その結果どうなるかと言うと、どこからでもこの継続を再開できるようになるのです。
例を示しましょう。
(define x ( ))
(begin
(display "こぶた")
(display "たぬき")
(call/cc (lambda (z) (set! x z)))
(display "きつね")
(display "ねこ"))
このプログラムを実行すると、xに空リストが束縛された後、
こぶた
たぬき
きつね
ねこ
と表示されます。
このとき、「次に(display "きつね")を評価する」継続が大域変数
x にバインドされていますので、
(x #t)
と x
にバインドされた継続を関数として呼び出すと、その継続から実行が再開されて
きつね
ねこ
という実行結果が得られます。この場合、call/cc呼び出しの戻り値は使われていないので、xを呼び出すときに用いた引数#tは結果として無視されます。
この機能を使えば、継続を用いてthrow/catch/finallyなどの大域脱出や、疑似マルチスレッドさえ実現できたりしますが、もう説明に飽きたので詳しくは書籍などを参考にしてください。私もアプリケーション開発の項で気が向いたら書くかもしれません。
継続の実装の問題点
さて、このように柔軟かつ強力な継続ですが、処理系の実装者としては実現が困難なのは言うまでもありません。
C/C++の機能でこれに近いのは、
setjmp/longjmpthrow/catch
ですが、これらは以前にも書いたように「内から外へ脱出する」ための機能であり、大域変数にバインドしていつでもそこから再開できるschemeの継続には使えません。
なぜsetjmp/longjmp及びthrow/catchでは「内から外への脱出」しかサポートされていないのでしょうか?
throw/catchは例外を構造的に扱うためのものだから目的だから仕様上当然だとしても、setjmp/longjmpもそうである必要はないように感じないでしょうか?
これは、C言語が関数呼び出しをどう扱っているか、という問題に関わっています。
C言語では、(多分言語仕様には含まれていないと思われますが少なくともデファクトスタンダード的には、)関数呼び出しをスタックを用いて実現します。
たとえば、再帰レベル7の関数呼び出しから8レベル目の関数呼び出しを行うとき、次のようにスタックをpushします。
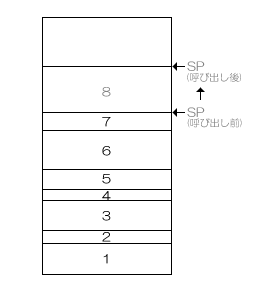
そして、8レベル目の関数呼び出しから7レベル目の関数呼び出しに戻るとき、覚えておいたスタックポインタを使って次のようにスタックをpopするのです。
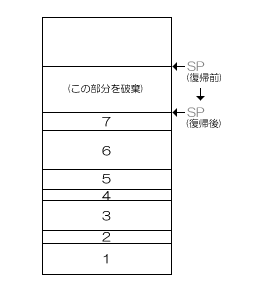
さて、翻ってsetjmpの実装を見てみましょう。setjmpの実装では普通、その時点でのCPUのレジスタを待避します。これには、スタックポインタも含まれます。
longjmpでは、setjmpで待避されたレジスタを復帰します。そのため、スタックポインタもsetjmp呼び出し時のものに戻されて、関数呼び出しの再帰レベルがsetjmp当時のものに戻るわけです。
C++のtry/catchでも動作は大体同じで、C++の場合はスコープから抜けたときにオブジェクトのデストラクタが起動されることがあるので、一気に戻らないで起動すべきデストラクタを起動しながら戻る点が違うだけ(だと思う)です。
ここで、setjmpで待避したレジスタを使って、setjmpした関数から抜けた後にlongjmpすることを考えてみましょう。
マニュアルのsetjmpの項でも見れば分かりますが、これは仕様外です。なぜでしょうか?
setjmp呼び出し時のスタック状態がこうだとしましょう。
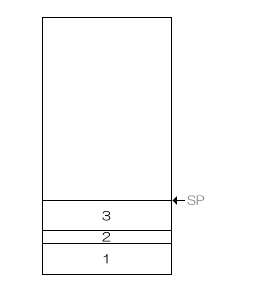
この時、setjmpを呼び出した関数から抜けていなければ、スタックの底からその時点でのスタックポインタまでの場所の情報は、setjmp呼び出し時から変わっていないことが保証できます。
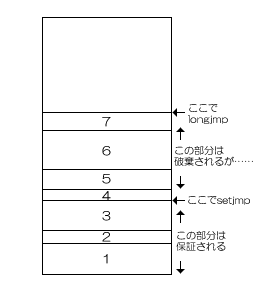
しかし、setjmpを呼び出した関数から抜けた後にlongjmpを呼ぶと、
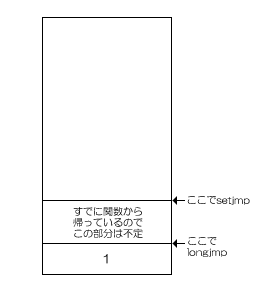
と、スタックポインタを復帰しても図で示した場所のスタックの内容自体が不定(別の関数呼び出しで使われているかもしれないから)になってしまうのです。そのため、マニュアルではこういうケースについて「結果を予測できません」と表現しています。
これを避けるには、setjmp時にスタックの底からスタックポインタまでの内容をすべて保存しなければなりません。当然ながら、ジャンプ用の待避バッファが大きくなる(当然時間がかかる)、動的メモリ割り当てを使ってもできるのかどうかは証明が困難(問題ない?)など、いろいろと問題が出てきます。逆に言うと、それを避けるための仕様が「setjmpを呼び出した関数から抜けた後のlongjmpの動作は不定」ということなのです。
結局、いつからでも実行の再開ができるschemeの継続の実装には使えません。
VSchemeではどうしたか
setjmp/longjmpを無理に使うなら、スタックの保存を自分でしなければなりません。しかしながらそれでは、アセンブラで書くよりほかなく、「ポータブルなコードを書く」という作戦目標の一つの実現が困難になります。DLLとしてのインターフェイスなどに使うならまだよいのですが、継続というschemeの根幹に関わる部分に使うわけにはいきません。
ではどうしたか。結局私は、内部構造を本当にバカ正直にに継続の連続にしました。もちろん代償はあります。setjmp/longjmpを使えないということは、大域ジャンプを含む実行の制御を独自に管理しなければならないということであり、そのためscheme関数の呼び出しにC言語の関数呼び出しシステムは使えないということです。
この独自の実行制御にはポイントが二つあります。
継続のスタック化
と
木構造スタック
です。
継続のスタック化
vschemeでは、継続のスタックを持っています。そして、次に実行されるべき継続はスタックの一番上に置かれています。そして、システムから呼び出された組み込み関数などで関数の再帰実行をしたくなったら、再帰実行する代わりに新しい継続を生成してそれをスタックの一番上に置き、そのままシステムに制御を戻します。システム側では、「実行すべき継続」がなくなるまで一番上の継続を消化しつづけます。
このスタック構造は、継続自身の「次の継続」ポインタによって実現されています。要するに、片方向リストのような構造になっているということです。
システムが継続を消化するとき、システムはこの継続を削除しません。継続も数値や文字列と言ったschemeオブジェクトの一種として実現されているので、ガベージコレクション時に削除されるため、それに任せているのです。
この削除しないことによって、継続をオブジェクト化したときにそれに続く継続が存在し続けることが保証されます。ガベージコレクションでは、シンボルなどから辿れるオブジェクトは削除されないため、継続がシンボルなどに束縛されていればそれと数珠つなぎにつながっている継続(=それに続く継続)も削除されないのです。
結果として、このような構造になります。
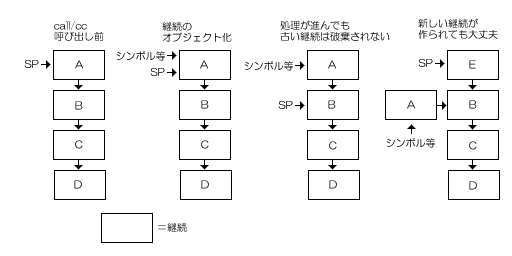
この方式の欠点は、再帰実行が必要になるたびにいちいち継続オブジェクトを生成するので、とても時間が無駄になることです。これについては、
- ある程度やむを得ない。
- 動的確保のスピードはヒープマネージャによってかなり違う。またC++で組んでおけばメモリ確保戦略はあとである程度カスタマイズできる(なんならヒープを使わないようにも)。
という判断から、とりあえず考えないことにしました。
木構造スタック
局所変数のバインドや関数呼び出し時に評価した引数などが保存されているスタックも、木構造になっています。前述のように、call/ccで継続を保存するときにはスタックの内容も保存する必要があるわけですが、スタックが木構造になっていれば、保存するのはスタックの一番上へのオブジェクトへのポインタだけでよいからです。継続スタックと同じ構造で、call/ccの呼出し後にスタックの本流が別の関数呼び出しのために変化しても、数珠つなぎでつながっている限りガベージコレクションで削除されることはないからです。
継続を消化するときには、スタックを指すポインタが継続が所持していたものに書き換えられます。これは、継続を関数呼び出しするときだけでなく、普通に継続を消化するときも同じです。そのため、vschemeでは、基本的にスタックをポップするという概念がありません。ポップするまでもなく、関数呼び出し(など)の前に作られた継続は、関数呼び出し前のスタックの状態を覚えているからです(実際には実装上のケチな都合で何個所かでポップに相当する処理を行っていますが)。
これらの理由から、vschemeにおける継続オブジェクトの呼び出しは大変高速になっています。ポインタを2~3個書き換えるだけだからです。といっても、周りが遅いので相対的に速いというか、継続を速くするためにまわりを遅くしているだけですが(笑)。まあポータビリティの確保のためにはこうするよりしょうがないんですけどね。
そのために組み込み関数、とくに特殊構文のコードが読みづらくなってしまったのが残念です。
将来的には、特殊構文を含む手続きの作成時(評価前には必ず作成する)には内部的にコンパイルする仕様にしようと思っています。
結構長くなっちゃいましたね。あ~あ。
(C) 1998 Naoyuki Hirayama. All rights reserved.
